MultistageRosettaScripts
Resource Usage For Precalculated Clustering
Back To Multistage Rosetta Scripts
- Written by Jack Maguire, send questions to jackmaguire1444@gmail.com
- All information here is valid as of Feb 15, 2018
Table of Contents
I benchmarked clustering cases of various sizes on the Wiggins computer in the Kuhlman lab. For each case, I measured how long it took and the peak memory usage (both shown below). The number of clusters was always equal to the number of elements divided by ten.
As you can see, the memory requirements become unreasonable before the runtime requirements do. This is due to the N-by-N matrix being calculated; hopefully there is an on-the-fly implementation of this protocol by the time you read this. As of now, it looks like you would not want to cluster with much more than 10,000 elements.
Runtime
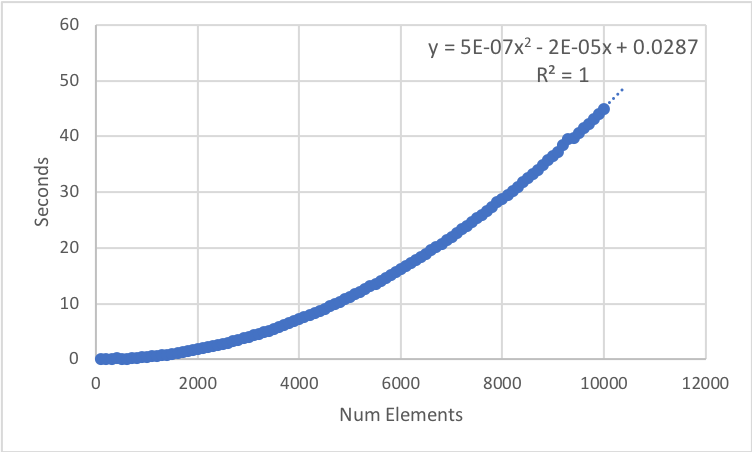
Using the fitted data, we can predict:
| Number of elements | Seconds | Minutes | Hours | Days | Years |
|---|---|---|---|---|---|
| 10 | 0.00005 | ||||
| 100 | 0.005 | ||||
| 1000 | 0.5 | ||||
| 10,000 | 50 | 0.8 | |||
| 100,000 | 5000 | 83.3 | 1.4 | 0.1 | |
| 1,000,000 | 500,000 | 8333.3 | 138.9 | 5.8 | |
| 10,000,000 | 50,000,000 | 833,333 | 13,889 | 578.7 | 1.6 |
Memory Usage
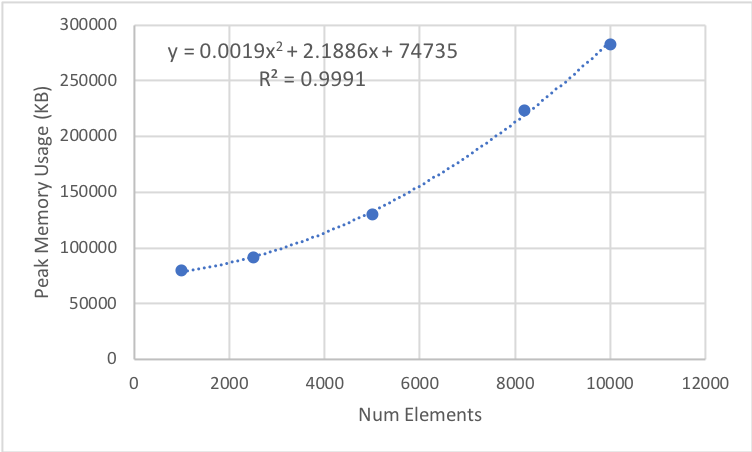
Using the fitted data, we can predict:
| Number of elements | KB | MB | GB |
|---|---|---|---|
| 10 | 74757 | 75 | 0.075 |
| 100 | 74973 | 75 | 0.075 |
| 1000 | 78824 | 78.8 | 0.079 |
| 10,000 | 286.6 | 0.29 | |
| 20,000 | 878.5 | 0.88 | |
| 30,000 | 1850 | 1.85 | |
| 40,000 | 3202 | 3.20 | |
| 50,000 | 4934 | 4.93 | |
| 100,000 | 19.3 | ||
| 1,000,000 | 1902 |