MultistageRosettaScripts
Stage Options
Back To Multistage Rosetta Scripts
Skeleton
<Stage
num_runs_per_input_struct=“(uint)”
total_num_results_to_keep=“(uint)”
result_cutoff=“(uint)”
max_num_results_to_keep_per_instance=“(uint)”
max_num_results_to_keep_per_input_struct=“(uint)”
merge_results_after_this_stage=“(bool)”
>
<Add mover=“” filter=“”/>
<Add mover_name=“” filter_name=“”/>
<Sort filter=“” negative_score_is_good=“true”/>
</Stage>
num_runs_per_input_struct
This is M.R.S.'s equivalent to the -nstruct command line option.
For the first stage, the number provided here declares the number
of times the stage will run for each structure defined by the <Job> tag(s).
For example, if num_runs_per_input_struct=40 and
there are 5 input structs (poses defined by the <Job> tags),
then the stage will end up running a total of 200 times.
For each additional stage, the number provided here declares the number of
times the stage will run for each result from the previous stage.
If num_runs_per_input_struct=5 for the current stage and
total_num_results_to_keep=10 for the previous stage,
then the current stage will end up running a total of 50 times.
total_num_results_to_keep
This number defines the maximum number of job results from the current stage that will survive
and go on to the next stage (or to be output, if this is the final stage).
Unlike num_runs_per_input_struct, this option is not affected by the number of input structs.
The combination of num_runs_per_input_struct=40, total_num_results_to_keep=10, and
5 input structs results in 200 jobs - of which only 10 results will survive until the next round.
max_num_results_to_keep_per_input_struct
A common hesitation to making num_runs_per_input_struct greater than 1 for a non-initial stage is that it might result in many near-duplicate results. In order to maintain diversity, you can use this setting to limit the number of results deriving from the same structure (result from previous stage) that are kept.
A value of 0 means that there is not limit (which is default).
result_cutoff
This options allows a stage to stop submitting jobs once a certain number of results have come in.
For example, say you are docking two proteins and you have some idea about how you want these proteins to interact.
You can run your docking mover as normal (with or without constraints)
and follow up the docking mover with one or more filters.
The job will not return a result unless it passes all of these filters
(including the one in <Sort>).
Now you can set num_runs_per_input_struct to a very large number and result_cutoff to 1000
and Rosetta will essentially keep sampling until it finds 1000 results that pass all of your filters.
max_num_results_to_keep_per_instance
Some movers can return multiple results (HBNet, for example).
This is challenging to handle in a well-organized manner.
The current format only allows for only the final mover in a stage to return multiple results.
This option defines a cap for a instance of that mover.
If this value is set to 10, for example,
a single instance of HBNet would only be able to return up to 10 results.
So if you have num_runs_per_input_struct=1000 and max_num_results_to_keep_per_instance=2,
you can get a maximum of 2000 results.
merge_results_after_this_stage
By default all of the results of a stage are thrown into the same pool,
sorted, and the top few are chosen to survive.
This option allows you to create a separate pool for each <Job> tag input struct until a certain point.
Suppose you have 2 <Job> tag input structs and
3 stages: (1) Dock, (2) Design, (3) Minimize.
Perhaps you want a 50/50 split of results until the final stage.
If you set merge_results_after_this_stage="true"/> in the second stage tag,
then you will have a 50/50 split of jobs until after the Design step.
All of the results of the Design step will go into the same pool
and the jobs for stage 3 will not necessarily be a 50/50 split.
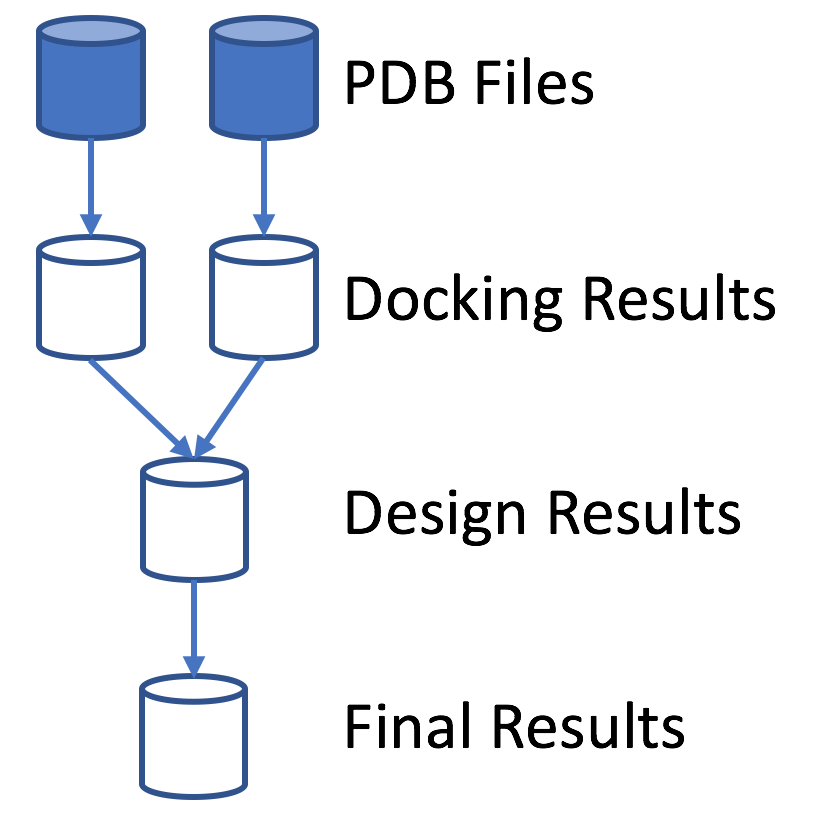
merge_results_after_this_stage can only be set to true for one stage.
If it is never present for any stage,
then results will always be placed into the same pool.
The values for total_num_results_to_keep and
result_cutoff are divided evenly into each pool.
For example, if result_cutoff="100" and you have 4 <Job> tag input structs
then the stage will not stop early unless each of the 4 pools has at least 25 results
and Rosetta will keep total_num_results_to_keep/4 results from each pool.
Add
<Add> means the exact same thing here as it does in
traditional rosetta scripts.
It takes up to 1 mover (can use either mover_name or mover)
and up to 1 filter (filter_name or filter).
If both a mover and filter are given,
then mover is applied before the filter is.
Sort
<Sort> is similar to <Add> but
only takes a filter (filter_name or filter).
The metric measured by this filter is used to sort the results
of this stage and determines which are kept and which are discarded.
More negative numbers are assumed to be better for this metric,
but this can be changed by setting negative_score_is_good="false".
See Also
- Multistage Rosetta Scripts
- Introductory RosettaScripting Tutorial
- Advanced RosettaScripting Tutorial
- Scripting Documentation: The Scripting Documentation home page
- Getting Started: A page for people new to Rosetta
- Application Documentation: Links to documentation for a variety of Rosetta applications