MultistageRosettaScripts
XML Scripting Format
Back To Multistage Rosetta Scripts
Summary
Every MRS script is a Frankenstein's Monster of the
JD3 XML format and
traditional rosetta scripts XML format.
The JD3 format consists of a <Common/> tag and one or more <Job/> tags
(the order of Common and Job depend on the specific application),
all within a <JobDefinitionFile/> tag as shown here:
<JobDefinitionFile>
<Job>
<Input>
</Input>
<Output>
</Output>
</Job>
<Job>
<Input>
</Input>
<Output>
</Output>
</Job>
<Common>
</Common>
</JobDefinitionFile>
MRS scripts use this foundation to make something like this:
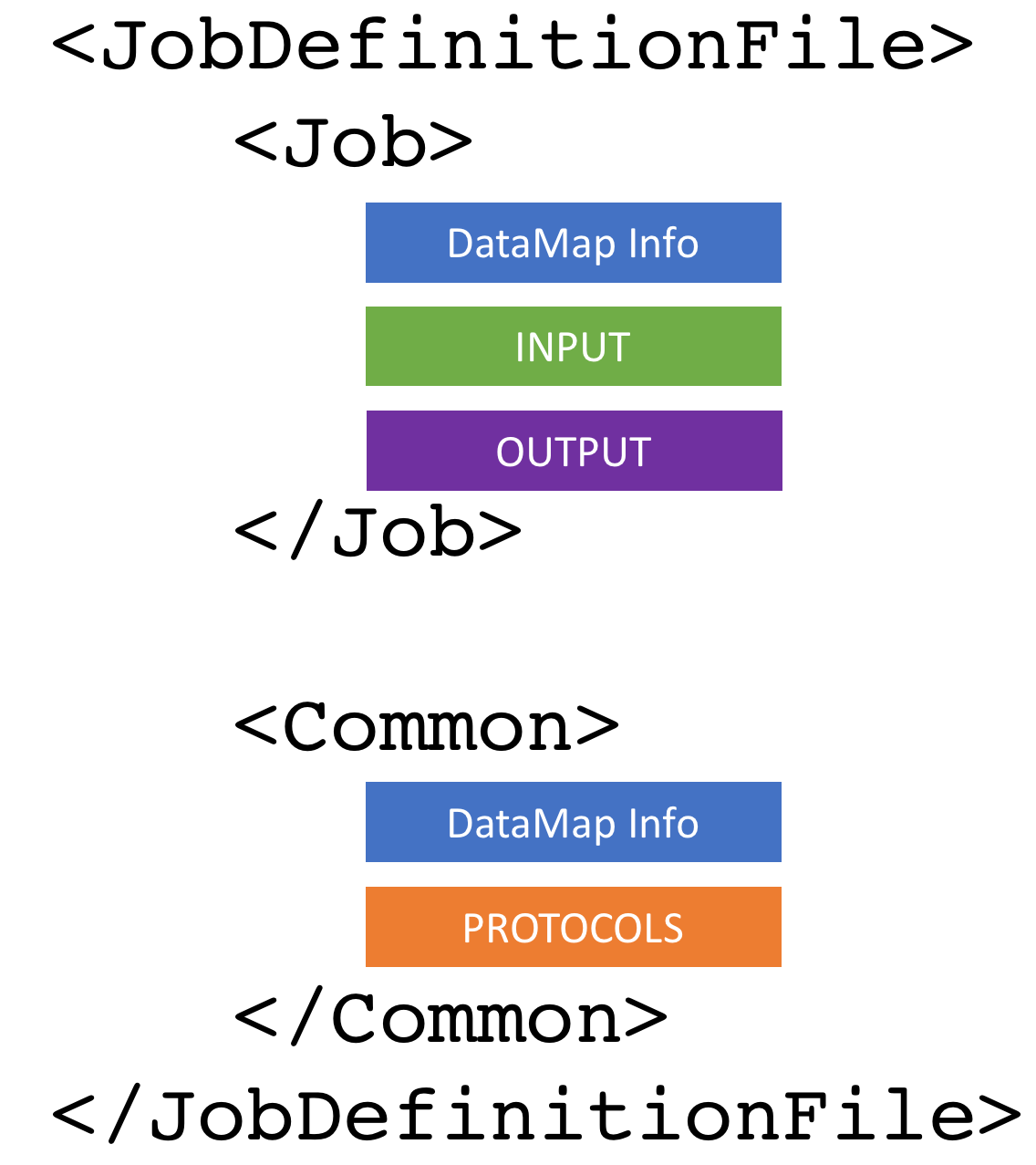
DataMap Info
This consists of everything from a normal rosetta script except for <PROTOCOLS>.
Score functions, residue selectors, movemap factories, task selectors,
movers, filters, etc. can all go in either <Common> or <Job>.
Rosetta will give the DataMap Info in <Job> higher priority in the case of a name conflict,
but only for trajectories that are spawned from that <Job> tag.
For example, you might have 3 <Job> tags and in one of them you put:
<SCOREFXNS>
<ScoreFunciton name="sfxn" weights="ref2015_cart.wts"/>
</SCOREFXNS>and in <Common> you have
<SCOREFXNS>
<ScoreFunciton name="sfxn" weights="ref2015.wts"/>
</SCOREFXNS>
<MOVERS>
<FastRelax name="fr" score_function="sfxn"/>
</MOVERS> In this case, FastRelax will use ref2015_cart.wts for one job and ref2015.wts for the other two.
All kinds of DataMap Info can be overloaded this way, including Movers and Filters.
See here for examples of how to use this feature.
Protocols
The <PROTOCOLS> section is the only one that behaves much differently than in traditional rosetta scripts.
Now, movers and filters are divided up into stages.
Between each stage, you have the opportunity to filter out trajectories based on their global ranking.
<PROTOCOLS>
<Stage num_runs_per_input_struct="10000" total_num_results_to_keep="5000">
<Add mover="m1"/>
<Add filter="f1"/>
<Sort filter="f2"/>
</Stage>
<Stage num_runs_per_input_struct="2" total_num_results_to_keep="5000">
<Add mover="m2" filter="f2"/>
<Sort filter="f1"/>
</Stage>
<Stage num_runs_per_input_struct="1" total_num_results_to_keep="2000">
<Add mover="m3"/>
<Sort filter="f2"/>
</Stage>
<Stage num_runs_per_input_struct="1" total_num_results_to_keep="1000">
<Add mover="m4"/>
<Sort filter="f2"/>
</Stage>
</PROTOCOLS>See here for a more detailed look into the options for <Stage>.
Input/Ouput
These tags are defined by JD3.
<Output> is optional, but you need to include <Input> to tell Rosetta how to load in your structure.
See the next section for a few examples on what a <Input> tag might look like.
Conversion
This format may be unwelcoming, but there is a way to convert an existing rosetta script into a multistage rosetta script without too much effor.
Say we have the following rosetta script saved as test.xml:
<ROSETTASCRIPTS>
<SCOREFXNS>
<ScoreFunciton name="sfxn"/>
</SCOREFXNS>
<RESIDUE_SELECTORS>
<Something name="res_selector"/>
</RESIDUE_SELECTORS>
<TASKOPERATIONS>
<ReadResfile name="read_resfile"/>
</TASKOPERATIONS>
<FILTERS>
<SomeFilter name="hi" selector="res_selector"/>
</FILTERS>
<MOVERS>
<FastRelax name="fr" score_function="sfxn" task_operations="read_resfile"/>
</MOVERS>
<PROTOCOLS>
<Add mover="fr"/>
<Add filter="hi"/>
</PROTOCOLS>
</ROSETTASCRIPTS>Running
multistage_rosetta_scripts.default.linuxgccrelease -convert -parser:protocol test.xml -job_definition_file msrs.xml(make sure -convert is the first argument) will create the following in msrs.xml:
<JobDefinitionFile>
<Job>
<Input>
<PDB filename="TODO"/>
</Input>
</Job>
<Common>
<SCOREFXNS>
<ScoreFunciton name="sfxn"/>
</SCOREFXNS>
<RESIDUE_SELECTORS>
<Something name="res_selector"/>
</RESIDUE_SELECTORS>
<TASKOPERATIONS>
<ReadResfile name="read_resfile"/>
</TASKOPERATIONS>
<FILTERS>
<SomeFilter name="hi" selector="res_selector"/>
</FILTERS>
<MOVERS>
<FastRelax name="fr" score_function="sfxn" task_operations="read_resfile"/>
</MOVERS>
<PROTOCOLS>
<Stage num_runs_per_input_struct="TODO" total_num_results_to_keep="TODO">
<Add mover="fr"/>
<Add filter="hi"/>
<Sort filter="TODO"/>
</Stage>
</PROTOCOLS>
</Common>
</JobDefinitionFile>Notice that the converter placed TODO's wherever the user still needs to make a decision. You can replace these TODO's using a text editor, but some of them can be filled in automatically if you give the converter enough information. For example, running
multistage_rosetta_scripts.default.linuxgccrelease -convert -parser:protocol test.xml -nstruct 50 -s 3U3B_A.pdb 3U3B_B.pdb -job_definition_file msrs.xmlcreates the following.
Now num_runs_per_input_struct is replaced by the command line value for -nstruct
and a <Job/> tag is created for every structure denoted with the -s and -l flags.
The converter is not currently smart enough to figure out if the input files are PDB files,
so it places a TODO comment for you to replace the input format if necessary
(see JD3 Options).
<JobDefinitionFile>
<Job>
<Input>
TODO: The script converter is not smart enough to know if this file is actually a pdb file. Please correct this tag if necessary!
<PDB filename="3U3B_A.pdb"/>
</Input>
</Job>
<Job>
<Input>
TODO: The script converter is not smart enough to know if this file is actually a pdb file. Please correct this tag if necessary!
<PDB filename="3U3B_B.pdb"/>
</Input>
</Job>
<Common>
<SCOREFXNS>
<ScoreFunciton name="sfxn"/>
</SCOREFXNS>
<RESIDUE_SELECTORS>
<Something name="res_selector"/>
</RESIDUE_SELECTORS>
<TASKOPERATIONS>
<ReadResfile name="read_resfile"/>
</TASKOPERATIONS>
<FILTERS>
<SomeFilter name="hi" selector="res_selector"/>
</FILTERS>
<MOVERS>
<FastRelax name="fr" score_function="sfxn" task_operations="read_resfile"/>
</MOVERS>
<PROTOCOLS>
<Stage num_runs_per_input_struct="50" total_num_results_to_keep="TODO">
<Add mover="fr"/>
<Add filter="hi"/>
<Sort filter="TODO"/>
</Stage>
</PROTOCOLS>
</Common>
</JobDefinitionFile>(Incomplete) Skeleton
If you really want to write a script from scratch instead of using the converter, here is a skeleton. This is missing most of the less common DataMap Info sections.
<JobDefinitionFile>
<Job>
<Input>
</Input>
</Job>
<Common>
<SCOREFXNS>
</SCOREFXNS>
<RESIDUE_SELECTORS>
</RESIDUE_SELECTORS>
<TASKOPERATIONS>
</TASKOPERATIONS>
<FILTERS>
</FILTERS>
<MOVERS>
</MOVERS>
<PROTOCOLS>
<Stage>
<Add/>
<Sort/>
</Stage>
<Stage>
<Add/>
<Sort/>
</Stage>
</PROTOCOLS>
</Common>
</JobDefinitionFile>See Also
- Multistage Rosetta Scripts
- Introductory RosettaScripting Tutorial
- Advanced RosettaScripting Tutorial
- Scripting Documentation: The Scripting Documentation home page
- Getting Started: A page for people new to Rosetta
- Application Documentation: Links to documentation for a variety of Rosetta applications